
Uses of hash tables
A hash table is a data structure that allows very fast retrieval of data, no matter how much data there is.
For that reason, hash tables are widely used in database indexing, caching, program compilation, error-checking, password authentication, and much more.
How does a hash table work
Consider a simple one dimensional array variable. To find an item in the list, you could employ a brut force approach, such as a linear search. This would involve checking each item in turn. For a very big array, this could take a very long time. However, if you happen to know the index number of that element you can look up the value very quickly indeed. In fact, the time it takes to look up any particular value in an array, if you know its index number, is independent of the size the array, and independent of its position in the array.
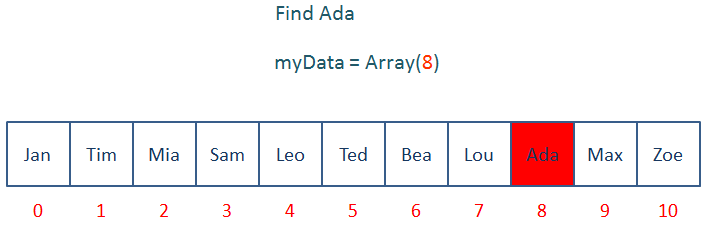
Loading the hash table
But how can you know which element of the array contains the value you’re looking for? The answer is that each index number can be calculated by using the value itself. So that the index number is in some way related to the value.
Here you can see that each item has been placed in the array according to a calculation. For example, the denary ASCII codes of the letters in the word Mia are added together, then this total is divided by the size of the array, in this case 11. The reminder of this calculation is 4, which is where Mia in placed in the array.
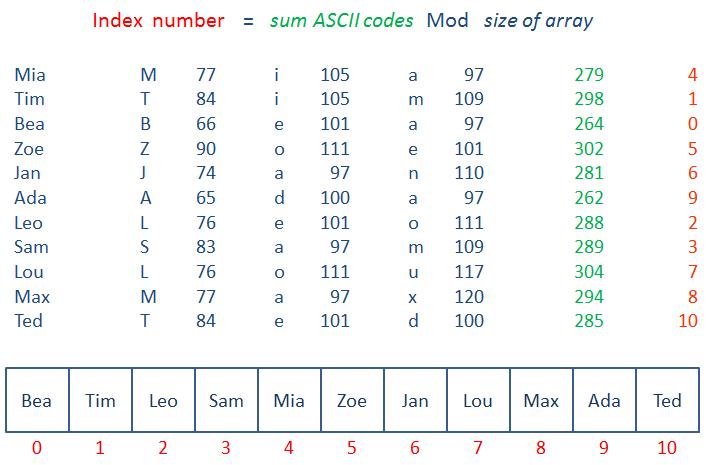
To retrieve an item, the same calculation is performed again. For example, to retrieve Ada the hash function is applied to the sum of the ASCII codes, 262 Mod 11 = 9, and the calculated index number is used to perform a fast array lookup.
Key-value pairs
Rather than storing just individual items of data, hash tables are often used to store key-value pairs.
For example, Ada’s name would be the key, which would be used to calculate the index, and her date of birth, the corresponding value.
For this reason, a hash table of key value pairs is sometimes referred to as a hash map.
To implement this, each element of the array could itself contain an array of 2 elements (one for the key and one for the value). An array of arrays is called a jagged array. Alternatively, each element of the array could contain an object with one property for the key and one for the value.
Objects in a hash table
If an object oriented approach was taken to the implementation of a hast table, each element of the array could contain an an instance of a class (i.e. an object) in which the key was just one of many different properties. By populating the array with objects, you can effectively store as much related data as you like, for each key.
The hash function
A hashing algorithm, also known as a hash function, is the calculation applied to a key, which may be a very large number or a very long string, to transform it into a relatively small index number that corresponds to a position in the hash table. This index number is effectively a memory address.
There are lots of ways the address can be calculated, some more appropriate than others, depending on the nature of the data. For numeric keys, it’s common to divide they key by the size if the array (n) and take the remainder. We say:
address = key modulo n
As you’ve seen, for alphanumeric keys, you can sum up the ASCII code of each character and divide this by the size of the array (n) to arrive at an address.
address = sum of ASCII code modulo n
The folding method is useful for keys such as telephone numbers. This involves dividing the key into equal parts then adding the parts together.
For example, the telephone number 01452 8345654, becomes 01 + 45 + 28 + 34 + 56 + 54 = 218
Depending on size of table, the sum is then divided by some constant and the remainder taken as the address.